Case Study
Introduction
Telegraph is a self-hosted, serverless Notification as a Service (NaaS) designed to simplify the complexities of implementing and managing real-time notifications for web applications.
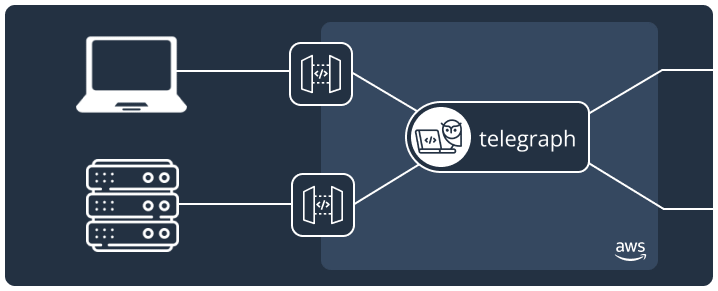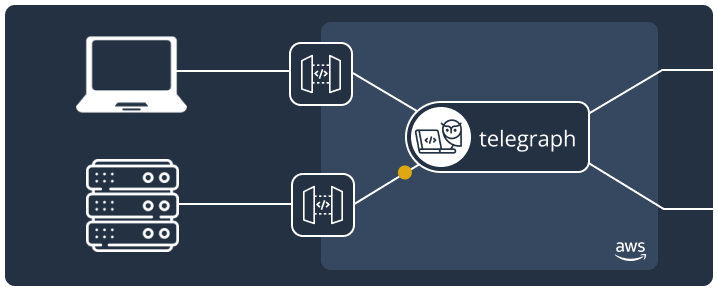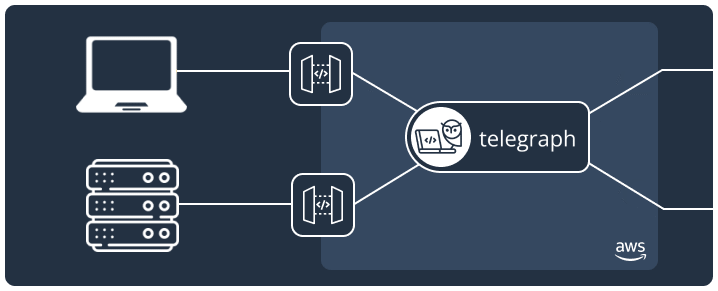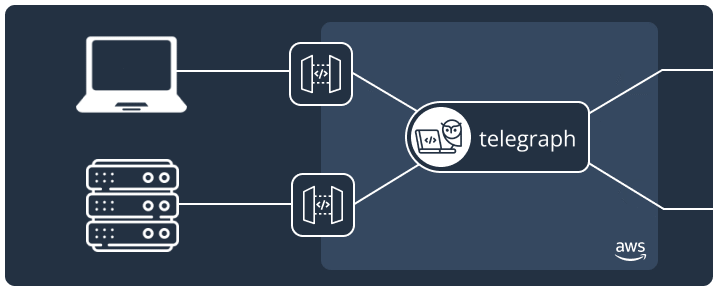
Notifications may seem simple on the surface. They’re just a way to keep users informed on things like a shipped package, an upcoming meeting, or a flash sale. Whenever one of these events happens, you send a message to your user. But when you start digging into what it takes to build a notification system of your own, it becomes apparent that there’s a lot more going on under the hood. It’s not just about delivering a message. How do you make sure it works without bogging down the rest of your application? How do you make sure it works for every user, every time? These challenges are not always obvious until you’re deep in the development process.
This case study explores the technical foundation of Telegraph, focusing on the challenges of building a scalable and reliable notification service, the architectural trade-offs made during its development, and the benefits of adopting a serverless approach.
Building Notifications is Not Trivial
Notifications are messages triggered by an event within an application that are sent to subscribed users. They can be delivered over multiple notification channels, which may include: web-push, in-app, email, or Slack. The first step in building a notification system is deciding what should trigger a notification. What events matter to you or your users? From there, you need to build a logic diagram to determine if a notification should actually be sent. Maybe the user has unsubscribed from this event type, or they’ve enabled do-not-disturb. Is the event critical enough to override those settings? It’s not just a few decisions, either. Just look at Slack's notification logic diagram – figuring out when to send a notification can quickly become a maze of decision-making.
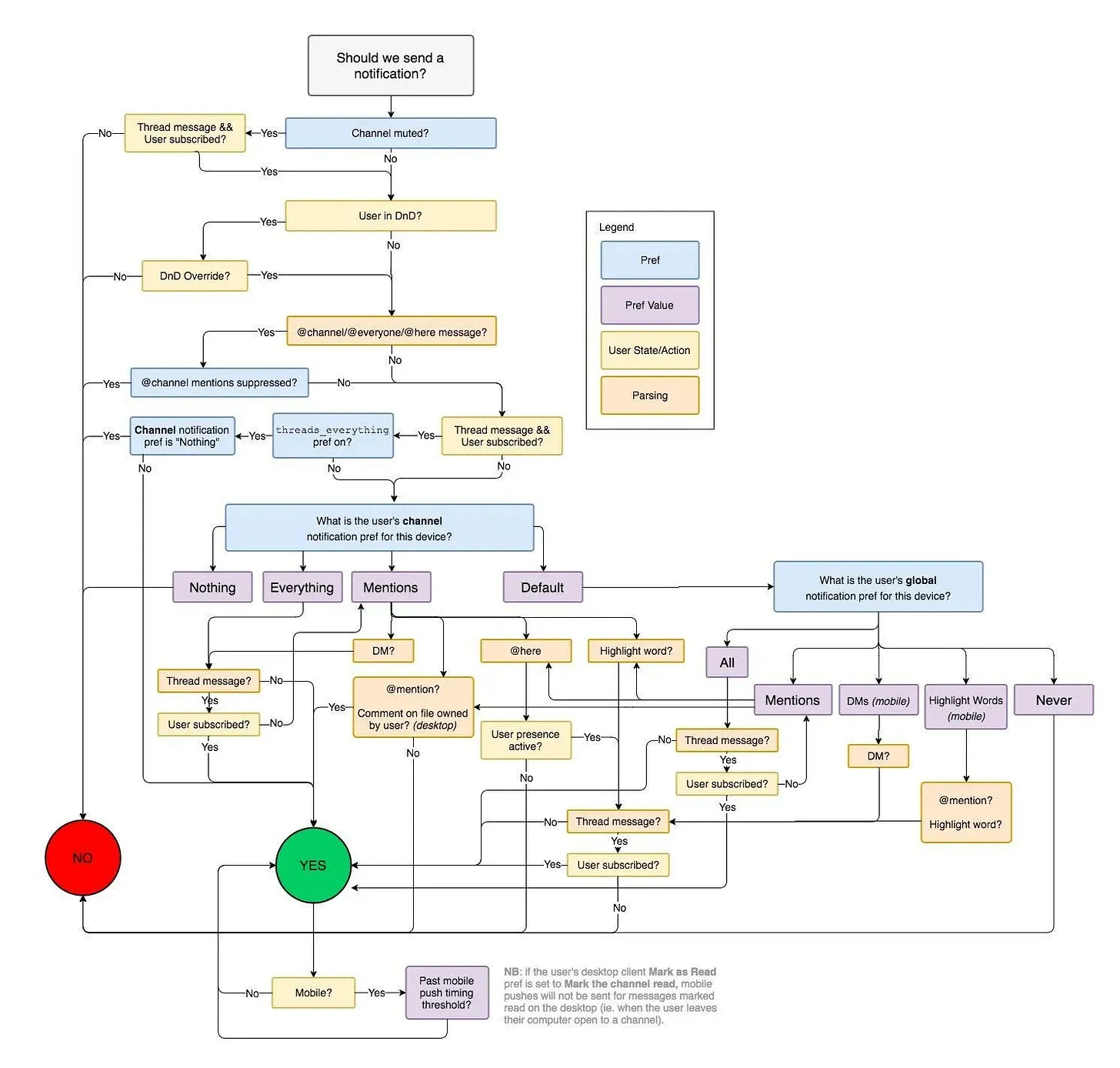
Once you’ve decided when to notify, the next challenge is how to deliver the message. Traditional HTTP request/response cycles aren’t designed for proactively pushing data to users. If you want to send messages without waiting for users to request them, you’ll need to make some architectural changes. And that’s only the beginning.
On a normal day, your app and the notification system can share infrastructure without issues. But when usage spikes -- whether it’s your app handling a flood of new users or the notification system sending out a burst of messages -- the story changes. Both systems are now competing for the same resources, and you could quickly run into capacity limits. What’s worse is that these surges tend to happen together. When your app is busiest, notifications tend to be as well. This overlap can strain your infrastructure in ways that are hard to recover from during a critical moment. So, when you add notifications, you’re also adding to your scaling concerns – and it’s something you’ll need to plan for.
Finally, users expect notifications to "just work," but there’s a lot that goes into making that happen. For developers, it’s not just about sending a message. It’s about making sure it actually gets delivered, keeping track of any failures, and knowing the status of each notification as it traverses through the system. What happens if something goes wrong during delivery? How do you know if the message reached its destination? These are things you’ll need to consider, and building the systems to track them adds a whole new layer of complexity. It’s easy to overlook this when you're focused on getting messages out the door, but without it, you’re left in the dark about whether things are actually working.
When you step back and think about all of this, it quickly becomes apparent that building a notification system isn’t just a quick add-on. It’s a whole project that can take a lot more time and effort than you might have expected.
Third-Party Solutions
The good news is that you don't have to reinvent the wheel. There are plenty of services out there that specialize in notifications. Of course, third-party solutions come with their own set of trade-offs. You’re giving up some control over how things work, and you might be tied to their pricing model. Open-source solutions may not have a recurring fee, but they’re not entirely “free” either. The real cost comes in the time it takes to get up and running with them. You could end up spending a lot of time just trying to integrate something open-source. However, in exchange, you get a system that’s already built to handle all of the complexities mentioned above.
Services like MagicBell, NotificationAPI, Novu, and Knock all bring something to the table. Knock and Novu are feature-rich, but they can be time-consuming to integrate. MagicBell and NotificationAPI are more straightforward, but their pricing starts at $100-$250/month and the free tiers come with mandatory branding. Another point of consideration is that using these services means storing user data on external systems, which may raise data privacy concerns.

Telegraph stands out in four key areas against the existing solutions:
- Open-source and self-hosted.
- Auto-deployment of all required AWS services with a CLI.
- Complete data ownership.
- Minimizes costs with the on-demand features of AWS. [1]
Introducing Telegraph
Telegraph is built for small to mid-sized applications that need to deliver real-time notifications. For developers choosing Telegraph, the service has pre-configured delivery channels and an observability dashboard for overseeing the service instance. Developers can then implement in-app, email, and Slack notifications into their applications with minimal structural changes to their existing infrastructure.
Telegraph is deployed to AWS via a CLI available as an npm package. Once deployed the backend SDK can be integrated in the customer’s backend to send notification requests and the TelegraphInbox React component can be added to the customer’s frontend, enabling in-app notifications and notification preference management for users.
Step 1: Install dependencies & deploy Telegraph to AWS
Install Telegraph CLI
$ npm install -g @telegraph-notify/telegraph-cli
Initialize Telegraph
$ telegraph init
Deploy to AWS
$ telegraph deploy
Step 2: Integrate frontend SDK
import { TelegraphInbox } from "@telegraph-notify/frontend-sdk";
<App>
<TelegraphInbox
user_id={<USER_ID>} // Unique identifier of the logged in user
userHash={<USER_HMAC>} // Hashed user_id
websocketUrl={<WEBSOCKET_GATEWAY_URL>} // WebSocket Gateway URL
/>
</App>
Step 3: Send notifications with the backend SDK
import Telegraph from "@telegraph-notify/backend-sdk";
// Enter secret key and HTTP Gateway URL
const telegraph = new Telegraph(secretKey, httpGateway);
telegraph.send({
user_id,
channels: {
in_app?: {
message
},
email?: {
subject,
message,
},
slack?: {
message,
}
}
});
Demo
Here is what all of that looks like in action.
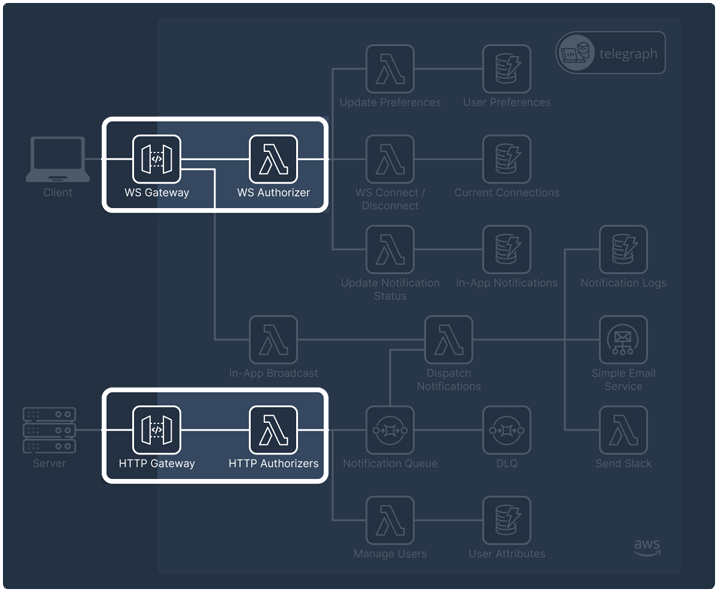
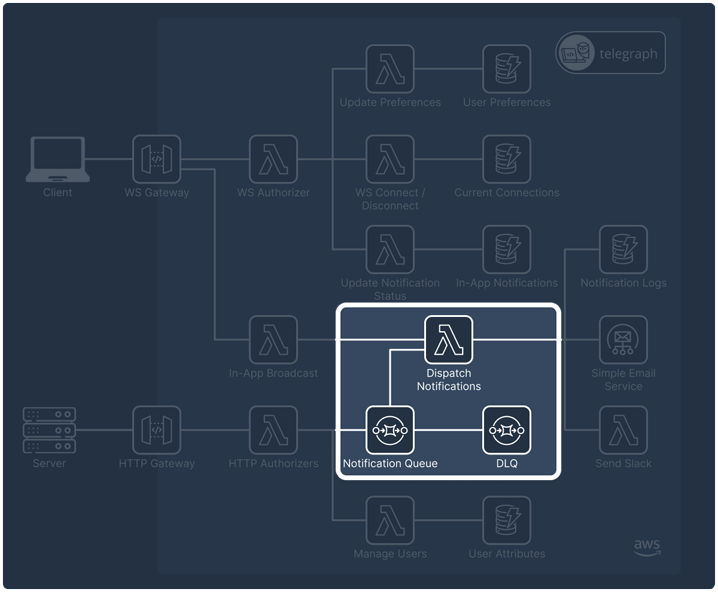
Architecture
Telegraph has a serverless architecture on AWS and uses services like API Gateway, Lambda, and DynamoDB to implement its service with minimal operational overhead.
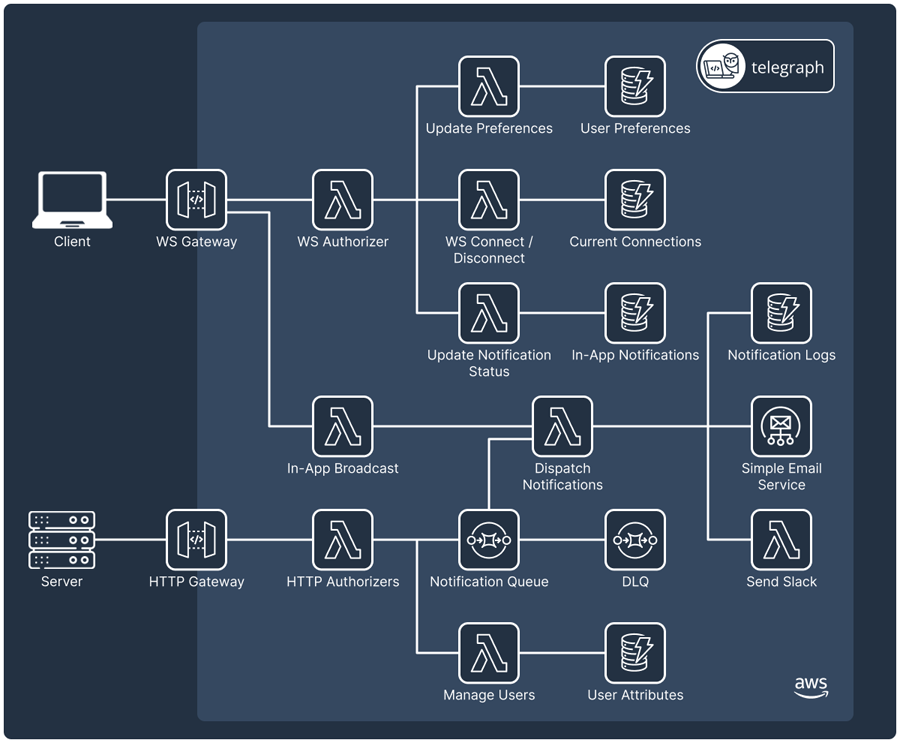
Engineering Challenges and Decisions
Real-time Communication with Clients
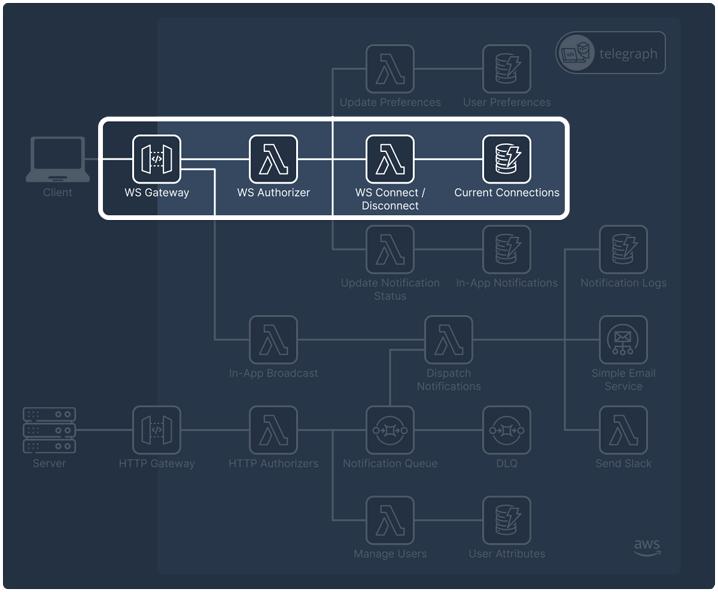
One of the first decisions we had to make was how to send in-app notifications to the client. In the standard HTTP model, clients request data from servers as needed. In-app notifications, however, require real-time delivery, where the server pushes data to the client as events happen without waiting for a request.
There are three primary mechanisms that can be used to achieve this: polling, Server-Sent Events (SSE), and WebSockets.
Polling
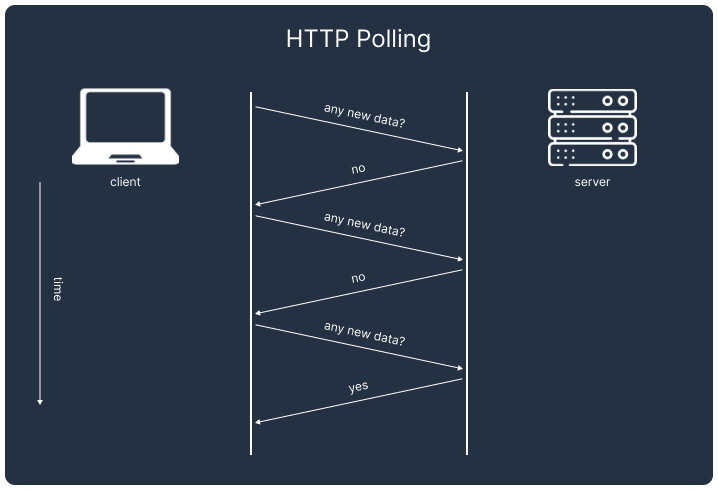
Polling is a mechanism in which a client periodically sends HTTP requests to a server to check for new data. However, frequent polling can strain both the server and the network. While increasing the interval between requests can alleviate that strain, it reduces the application's ability to deliver real-time updates. Additionally, as the user base grows, the number of unnecessary polling requests – those that return no new data – can result in a substantial waste of resources. Due to these inefficiencies, especially at scale, we opted not to use polling.
Server-Sent Events & WebSockets
Both SSEs and WebSockets establish a persistent connection between client and server and allow data to be pushed on-demand from the server to the client.
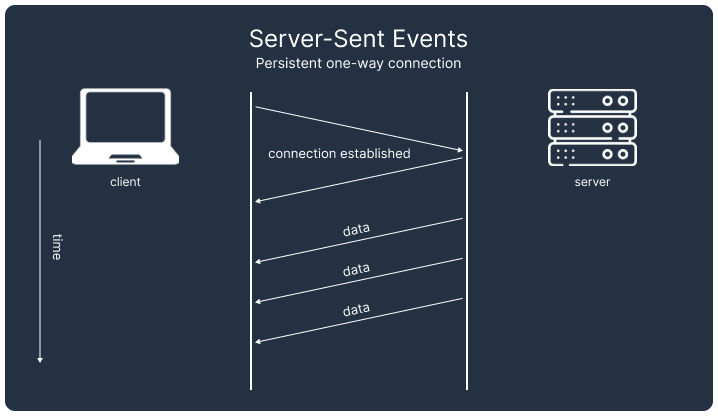
SSEs establish a long-lived HTTP connection between the client and server, enabling the server to push updates to the client as they occur and only terminate when requested by either party. Compared with WebSockets, SSE is simpler to implement, as it relies solely on standard HTTP without requiring additional libraries or protocols. This simplicity makes it easy to set up and debug. Furthermore, SSE provides built-in features like automatic reconnection and message ordering.
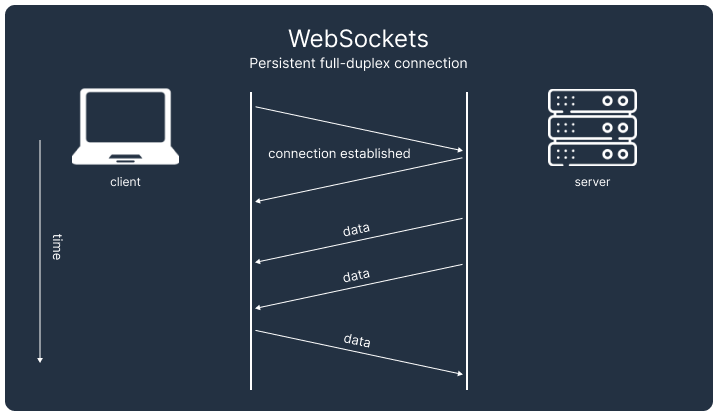
WebSocket is a communication protocol that establishes a long-lived, bidirectional connection between a client and server over a single TCP connection. Following the initial HTTP handshake, the client sends an upgrade request that transitions the connection to the WebSocket protocol. This protocol establishes a dedicated channel for two-way real-time communication, making WebSocket particularly well-suited for interactive use cases, such as real-time chat applications or collaborative tools.
Why WebSockets?
We initially used SSEs to implement the sending of in-app notifications. The browser received these events from an Express backend server and then updated a user-facing frontend component to notify the user of this new event. This mechanism fulfilled our requirement to send in-app notifications in real-time. However, when we considered the scaling implications of using SSEs, and compared this with a serverless WebSocket architecture, we found WebSockets would serve Telegraph’s use case better in the long term, particularly when considering the availability of AWS API Gateway for WebSockets.
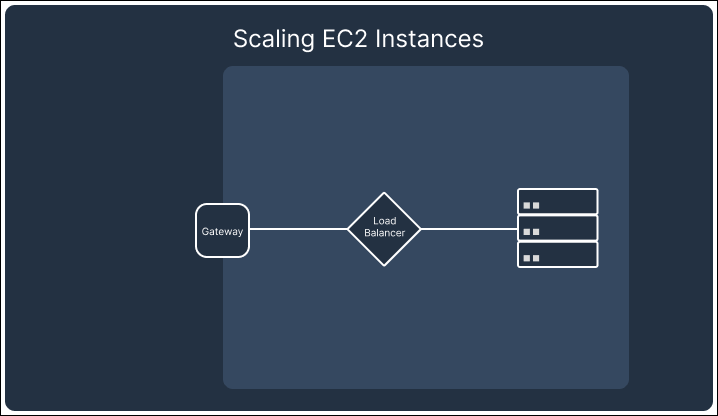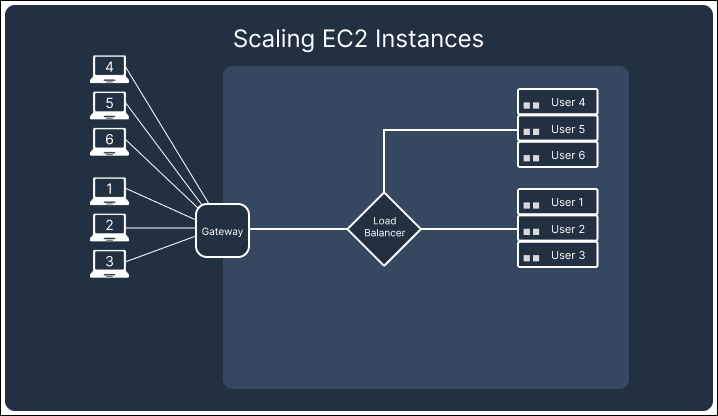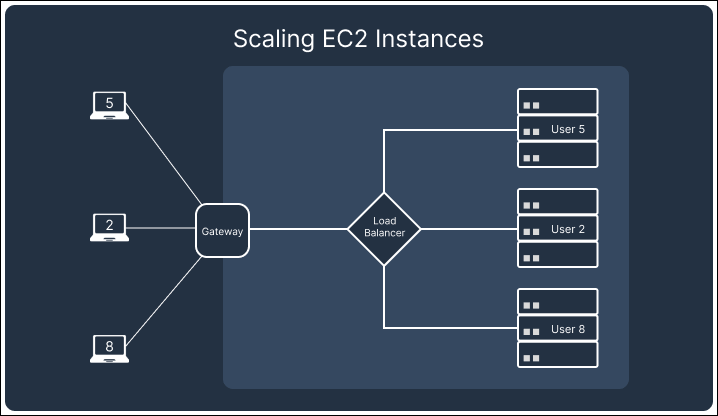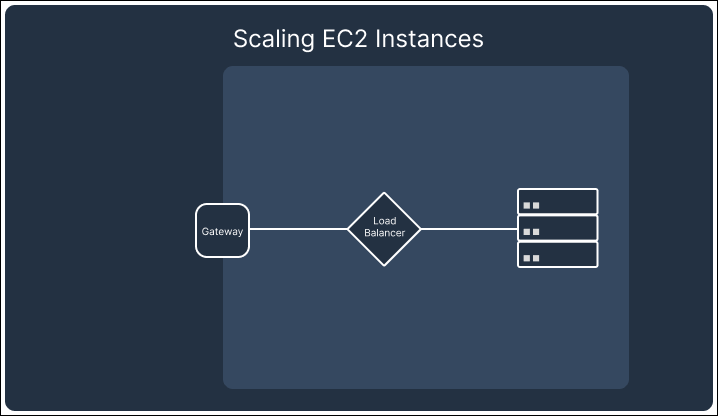
If we were to continue building Telegraph as a drop-in Notification as a Service using SSEs, we would have needed to set up an EC2 instance or similar compute resources. While this solution provides fine-grained control over scaling logic, connection management, and database infrastructure, we found it to lead to higher costs and complexity. For example, scaling an EC2-based setup would involve managing load balancers and provisioning distributed database systems or sharded architectures to handle the growth in notification data. These resources will incur costs even when idle. We estimated that in a hypothetical use case of delivering 100,000 notifications for 2,000 users, the monthly cost of the serverless architecture was about 1/3 of that of using EC2 instances.
In addition to architectural components needing to scale up, as traffic drops and the number of connections reduces, they also need to scale down while maintaining the remaining connections. Although a single EC2 instance may be able to service all active SSE connections, we would not be able to consolidate the scattered connections without disconnecting them first. This would result in multiple EC2 instances running in underutilized states.
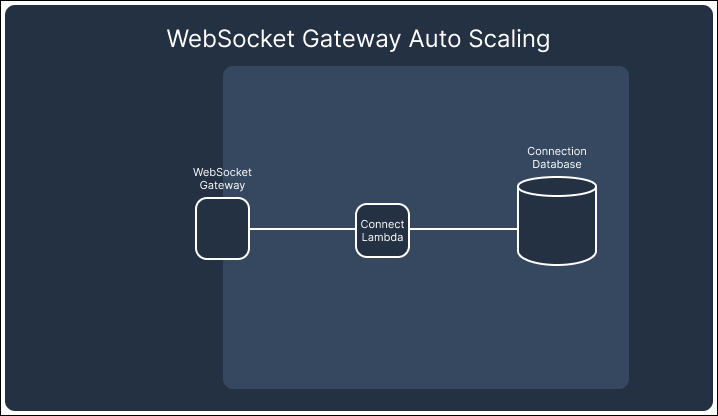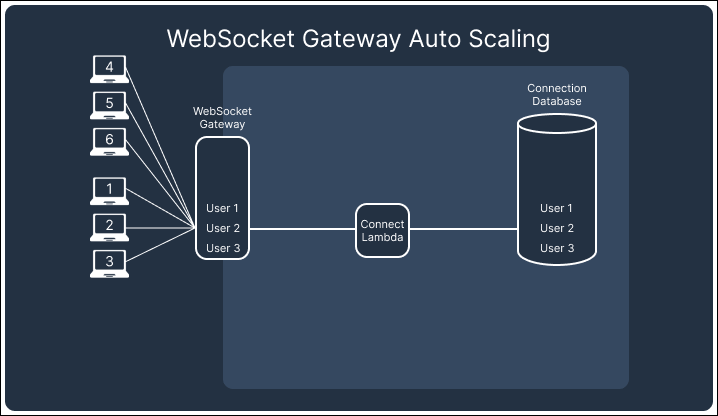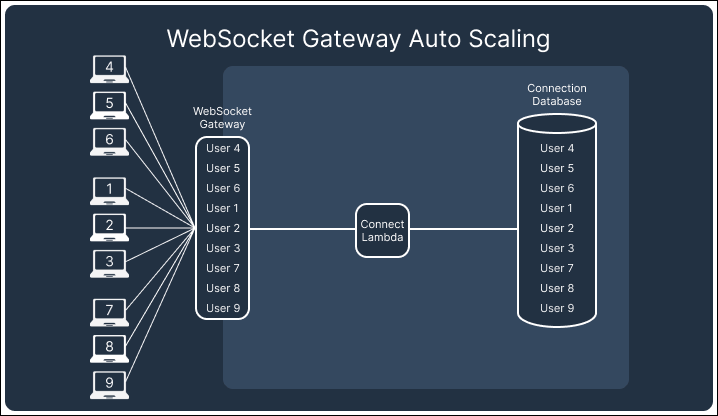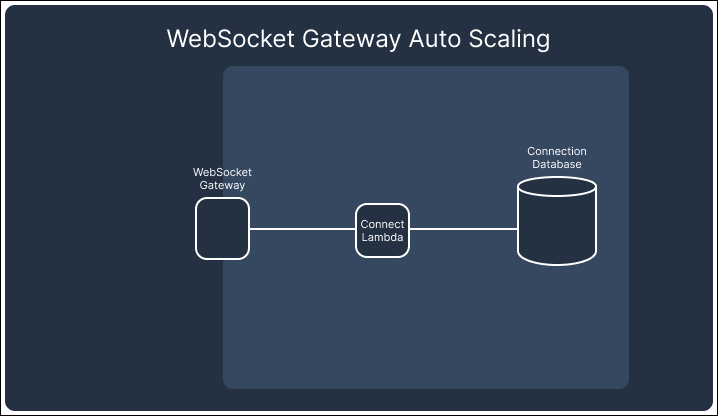
In contrast, AWS’s API Gateway Websocket API automatically handles scaling and connection persistence. The API Gateway and the attached lambdas scale up and down with demand, ensuring no redundant resources are left running that would drive up costs. This built-in scaling behavior of the API Gateway allowed us to focus on building the core functionality of Telegraph while minimizing the operational burden of managing infrastructure, making WebSockets the better choice for our notification system.
Persistent Data Storage
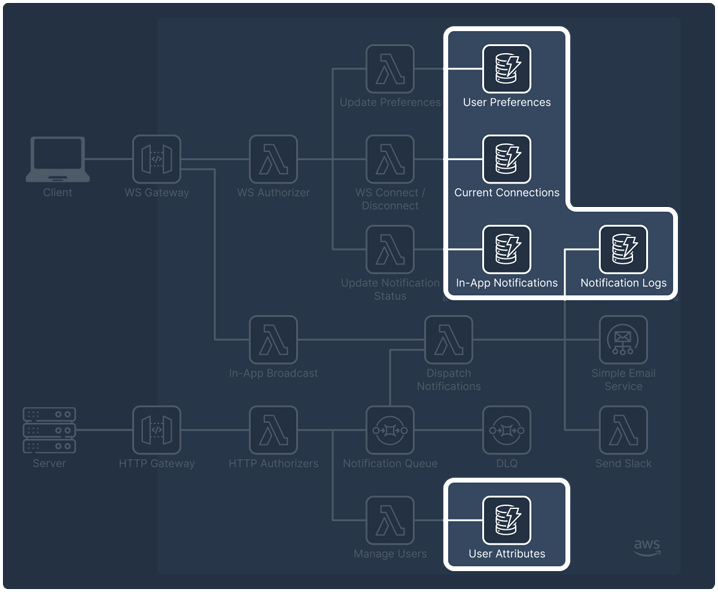
Storage for high reads and writes
Our data for WebSocket connection IDs, user preferences and attributes, and in-app notifications has a fixed and consistent structure. It also does not require complex relational queries, primarily involving simple look-ups based on user ID. However, the nature of our workflow meant that the database solution needed to handle a high frequency of both reads and writes.
By this point, we had already committed to using the WebSocket API Gateway, which influenced the rest of our architecture. As a result, we considered database services offered by AWS that could integrate with our serverless infrastructure. Although we could potentially use either NoSQL or SQL databases since our data is structured, we ultimately chose a NoSQL database, specifically DynamoDB, due to its ability to scale horizontally and handle high read and write throughput.
Storage for high writes and large volume
Another type of storage solution we needed to consider was for the tracing logs of notification requests. This storage solution would need to handle a high volume of writes and store a large number of small files.
Initially, when considering storage for logs, Amazon’s S3 bucket seemed like the best choice. S3 is a scalable object storage solution known for being particularly cost-effective for storing large amounts of data. However, after implementation, we quickly found that the number of reads to the S3 Bucket would be significant and, with about a 10x difference in read costs compared to DynamoDB, it could quickly become an expensive solution. We also found the query time of S3 to be a significant concern for our use case, as retrieving 20 objects, each about 30 bytes, resulted in a timeout due to Lambda's default 3-second execution limit.
Given that we needed to query the logs database for viewing and error handling on the dashboard, the lag in retrievals and the cost difference for reads outweighed the cheap storage benefits of S3. As a result, we opted to use DynamoDB for our notification logs.
Once our data was stored away, it was time to keep it safe.
Authentication
Telegraph uses two authentication methods: key-based authentication for server-side connections and Hash-Based Message Authentication Codes (HMAC) for client-side connections.
Key-based Authentication

Telegraph uses key-based authentication for API requests. During setup, users generate a secret key, which is included in the Authorization header of each request and then verified by the HTTP Gateway authorizer.
Hash-based Authentication

Authenticating a client between two servers with a shared secret key is more challenging, since the credentials in the Authorization header are visible to the client. If the secret key is intercepted by a third party, they gain access to all Telegraph API functions.
Our solution uses hash-based message authentication codes (HMAC) [3] to authenticate clients connecting to the WebSocket Gateway. The application server generates a unique hash for each client by combining the secret key and user ID using SHA256. When connecting to the WebSocket Gateway, the user ID and hash are passed to the WebSocket authorizer, which verifies it using the same algorithm as the application server.
You might be wondering why we didn’t use JWTs or OAuth. After all, they’re widely adopted across the industry for authentication. The choice came down to what Telegraph is optimized for. HMAC avoids the need for additional infrastructure like token servers or complex validation workflows. You only have to manage a shared secret key.
JWTs and OAuth are powerful tools, but they’re designed for different needs. JWTs are great in distributed systems where multiple services need to independently validate tokens without checking back with a central server. That flexibility is great if you need it, but it adds unnecessary complexity for Telegraph’s needs. OAuth, on the other hand, is great for scenarios involving delegated access, like when users need to log in through a third-party provider. However, we designed Telegraph to be a single-tenant, self-hosted environment where your server already authenticates clients before Telegraph comes into the picture.
That said, we did recognize that the secret key used in the HMAC process doesn’t have a native expiration or rotation mechanism. We added a way for you to change the secret key whenever needed through the CLI – whether it’s in response to a security breach or simply because the key has been in use for a while and you want to rotate it out.
Observability
An integral part of our system is giving developers visibility into whether notifications are being delivered successfully and providing a way to debug failures when they happen. Telegraph enables detailed logging across all Lambda functions and gateways using AWS CloudWatch. Though thorough, the sheer volume of logs generated can make diagnosing issues with CloudWatch logs alone difficult.
Our dashboard is meant to act as a bridge between visualizing your Telegraph instance and diagnosing problems using CloudWatch logs. It provides a quicker, more user-friendly way to interpret metrics, logs, and failed messages. Developers can use the notification logs generated for a notification request to narrow their search of CloudWatch logs and resolve problems faster.
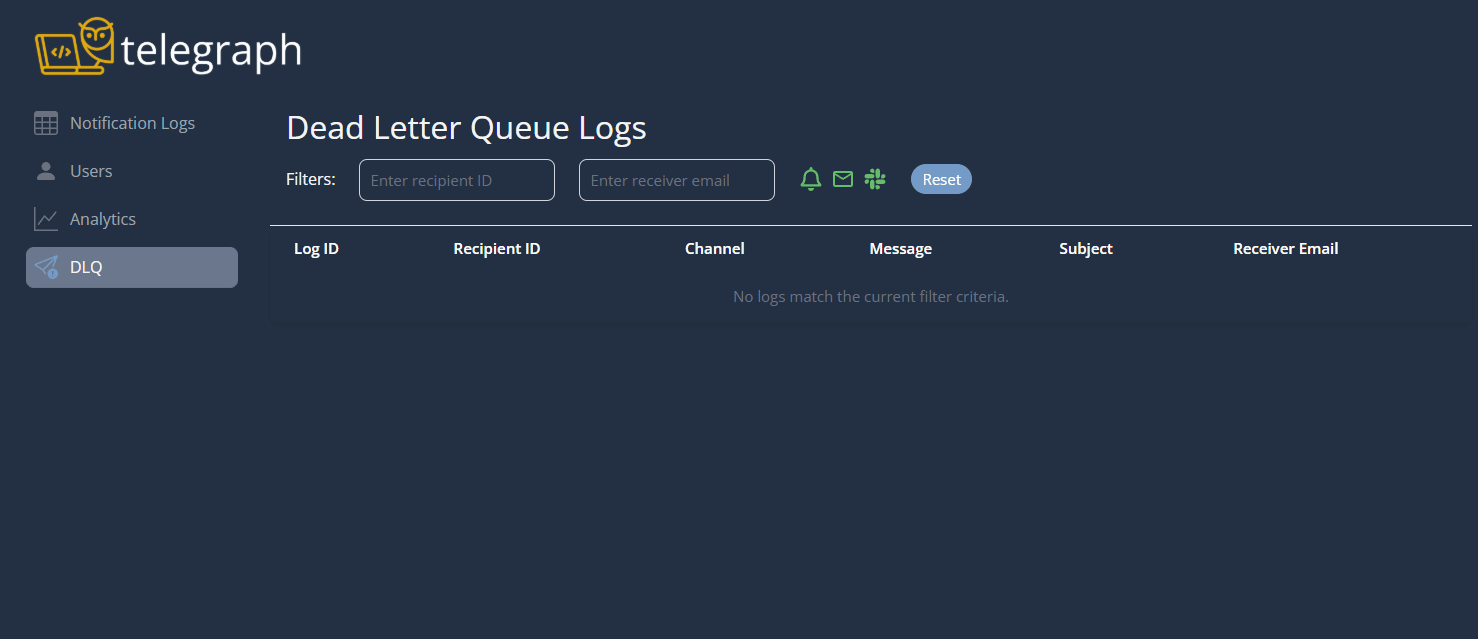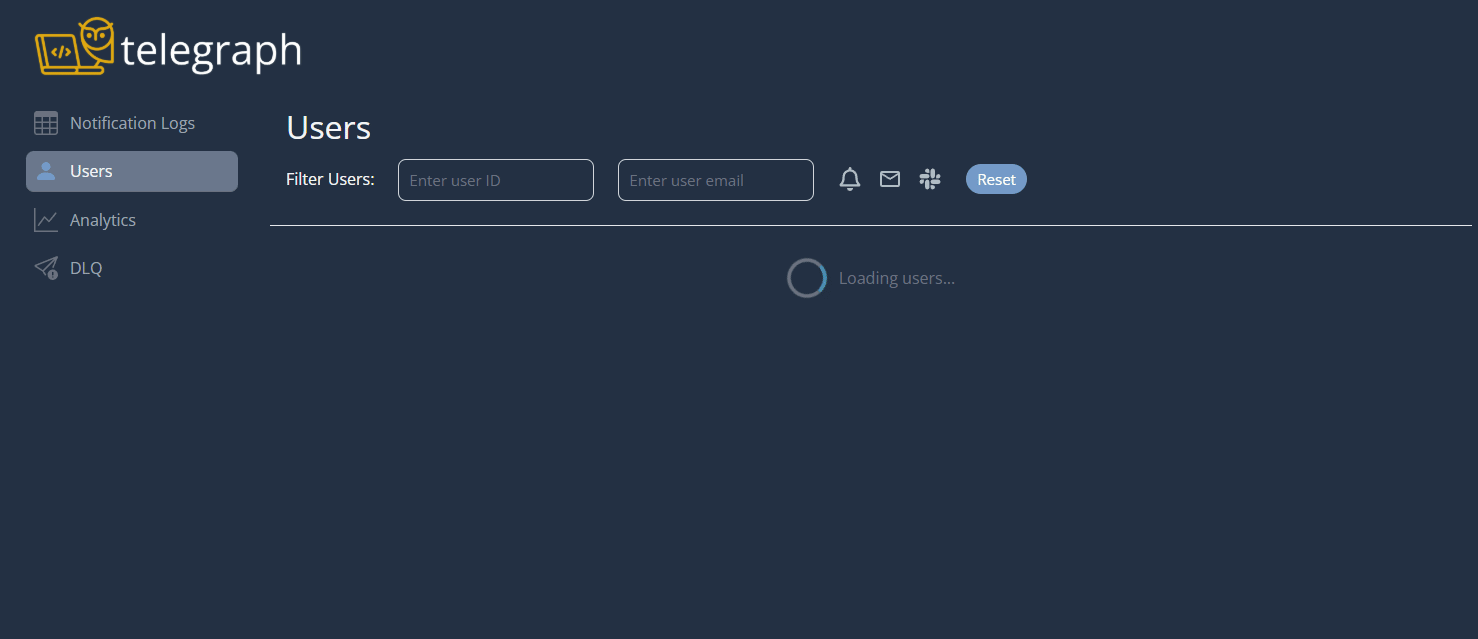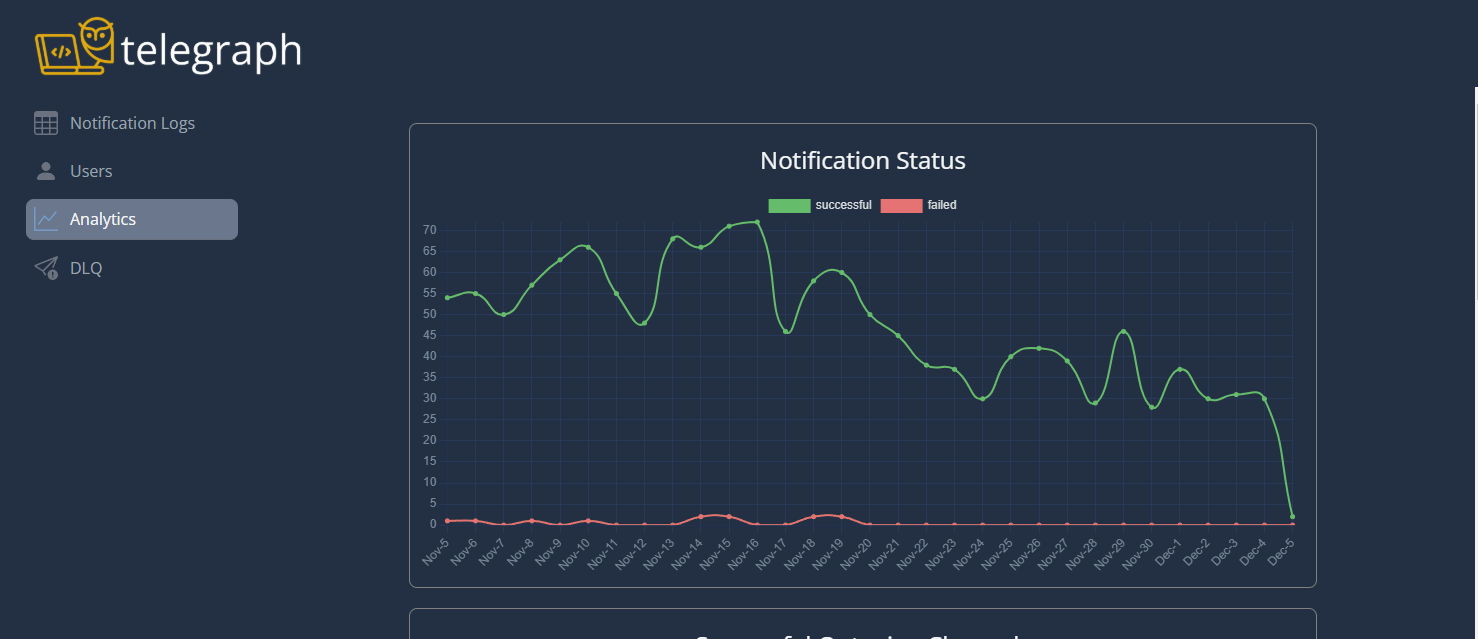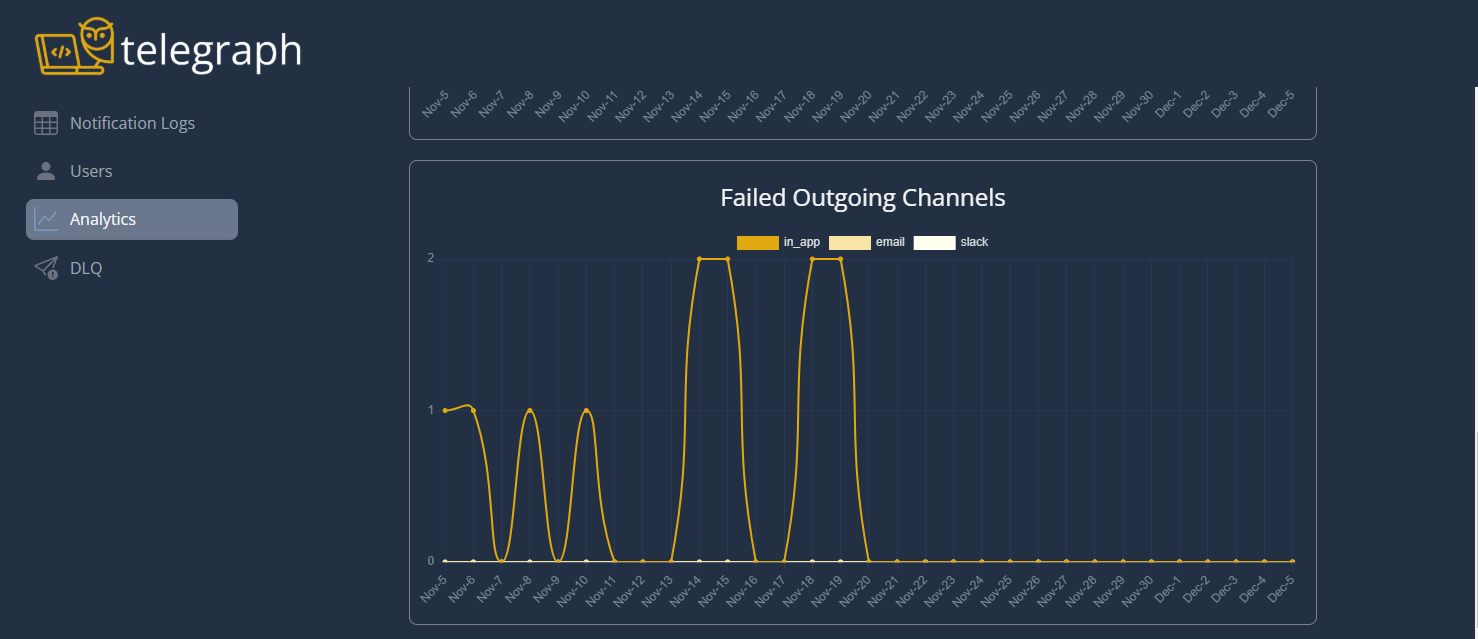
Traffic Spikes
Handling traffic spikes is one of the tricky parts of building a notification system. Even though AWS Lambda scales automatically, there are concurrency limits, and DynamoDB, while it auto-scales, has its own read and write rate limits. We wanted to make sure Telegraph could handle sudden surges in traffic without hitting those limits and causing issues. To manage this, we added a queue to rate limit the traffic flowing through the system.
AWS offers two types of queues: FIFO and Standard [4]. A FIFO queue, as the name suggests, processes messages in the exact order they are received. This seemed like a nice feature, but it was not strictly necessary for our use case. The downside of a FIFO queue is that it has a throughput limit of 300 requests per second. Also, to preserve the ordering of the messages, if there is an error processing a batch, all unprocessed messages have to go back to the queue. Since the queue uses the number of times a message appears in the queue as its criteria for sending that message to the dead letter queue (DLQ), this meant that it was possible for a message to be sent to the DLQ without ever being attempted to be processed.
A Standard queue forgoes enforcing FIFO behavior and is instead optimized for high message throughput, which Amazon states is unlimited. Without the strict first-in-first-out ordering rules, this meant we could process a batch of messages returning only the failed messages to the queue and eliminate the risk of a valid message being inadvertently sent to the DLQ. With these cumulative benefits, we decided to choose the Standard queue.
To then use the queue as a rate limiter in our system, we configured the Lambda consuming from it. The Lambda takes up to 100 messages from the queue with a concurrency limit of 10, creating a ceiling on the number of notification requests that are processed at a given time. Buffering requests and processing them asynchronously allows us to keep downstream components from being overloaded during spikes in traffic.
Load Testing
To ensure that Telegraph could handle high traffic scenarios and scale effectively, we conducted load testing on the key entry points of the application: the WebSocket Gateway and the HTTP Gateway. The objective of the testing was to evaluate our capacity under heavy loads, focusing on whether the connection requests would be successfully passed on to the integrated lambdas. We simulated a high volume of simultaneous users and interactions using artillery.io and a high capacity EC2 instance (32 vCPU, 128 GiB memory).
WebSocket Gateway
The WebSocket Gateway was tested to evaluate how it handles a high volume of connections. We started with a low connection rate to establish a baseline and gradually increased the load. Throughout the tests, latency remained consistent, and we didn’t encounter any errors. This confirmed that the WebSocket Gateway can handle up to 500 new connections per second, aligning with AWS's specifications. [1]
| Metric | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Test Duration | 20 | 20 | 600 |
| Maximum connections per second | 10 | 200 | 500 |
| Total Connections | 200 | 1239 | 291126 |
| Latency (ms) | 38 | 26 | 21 |
| Errors | 0 | 0 | 0 |
HTTP Gateway
For the HTTP Gateway, the focus was on API request handling. At light and moderate request rates, the system was able to process all requests. However, at a heavy load of 8,000 requests per second, we hit the AWS Lambda's regional concurrency limit of 1,000 [2]. This caused about 1.6% of requests to be throttled, as there weren’t enough Lambdas available to process them. Despite this, the requests that were processed maintained stable latency, and no errors occurred.
| Metric | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Test Duration (seconds) | 30 | 60 | 60 |
| API Requests per second | 5 | 100 | 8000 |
| Total Requests Made | 150 | 6000 | 480000 |
| Throttled Requests | 0 | 0 | 7854 |
| Latency (ms) | 156 | 44 | 78 |
| Errors | 0 | 0 | 0 |
Bottlenecks
The main performance bottleneck for Telegraph was the Lambda concurrency limit. While components like API Gateway and DynamoDB scaled well during load tests, Lambda’s default concurrency cap of 1,000 executions per region imposed by AWS became a limiting factor. This limit wasn’t reached during the WebSocket Gateway tests, but when the HTTP Gateway test ramped up to 8,000 requests per second, throttling began as all 1,000 Lambdas were already in use.
Capacity
Based on our results, we estimate that this bottleneck can be avoided if WebSocket connections are kept under 500 per second and API requests stay below 5,000 per second. These limits align well with our target use case of serving small to medium-sized applications. Moreover, AWS’s flexible concurrency limits offer an additional buffer, allowing Telegraph to scale even further if needed.
Future Work
Automated Key Rotation for HMAC Authentication
Our HMAC-based authentication approach, while robust, currently has two notable limitations: the lack of expiration and the absence of automated secret key rotation. Automating secret key rotation using a secure key management system like AWS Key Management Service would mitigate risks by periodically updating keys.
Stage-Specific Metrics
To improve the observability metrics of our dashboard, we could enhance its granularity by providing detailed insights into each stage of the notification delivery pipeline. Currently, the dashboard displays notification logs, their status, and timestamps, but it lacks visibility into where failures occur within the process. By incorporating stage-specific metrics, such as whether the notification failed during API processing, message queueing, or client delivery, we can offer a more precise diagnosis for failures. Additionally, integrating visualizations like success/failure rates, retry attempts, and latency distributions across stages would enable users to understand performance bottlenecks better and identify trends. These improvements would enable users to troubleshoot issues more effectively and optimize their notification workflows.
Automating Retry Logic for Failed Deliveries
Currently, the system lacks built-in retry logic for failed notification deliveries. While failed deliveries are logged and displayed on the dashboard, any reattempt to send these notifications must be done manually. Introducing automated retry logic to attempt delivery two or three times before marking a notification as failed could reduce the likelihood of prematurely abandoning notifications.
Footnotes
- Under typical AWS usage scenarios, delivering 10,000 notifications with Telegraph incurs an estimated monthly cost of $14